


Tecnologie per Sistemi di Visione Artificiale
Siamo distributori di componenti hardware e software per acquisizione ed analisi immagini per sistemi di visione industriale, sorveglianza avanzata, sistemi medicali, ricerca scientifica ed altro.

TELECAMERE INDUSTRIALI
Matriciali, lineari, infrarosse, termiche.

SMART CAMERA E SENSORI DI VISIONE
Smart Camera, Sensori di Visione.

SISTEMI DI VISIONE ARTIFICIALE 3D
Sensori e Telecamere 3D per applicazioni di visione industriale.
VISIONE EMBEDDED
Smart camera, telecamere su scheda, kit di sviluppo.

LETTORI DI CODICI
Lettori di codici 1D e 2D, fissi e portatili.

ILLUMINATORI INDUSTRIALI
Illuminatori LED, IP 65-66 alta potenza

OBIETTIVI MACHINE VISION
Ottiche, obiettivi varifocali, zoom.

FILTRI
Bandpass, longpass, shortpass, polarizzatori.

FRAME GRABBER
Schede di acquisizione, video converter.

SOFTWARE
Librerie di visione...

PC INDUSTRIALI
PC box machine vision, PC industriali fanless.
ACCESSORI
Cavi, custodie protettive, staffe e supporti.
PRODOTTI IN EVIDENZA
Sistema di Visione VS40

Sistema di visione Zebra configurabile sia come Smart Sensor che come Smart Camera, a seconda della licenza installata..
Telecamera UV Atlas10

Telecamera UV Lucid Video Labs ideale per acquisizioni nello spettro dell’ultravioletto nel range 200-400 nm..
Telecamera 3D Photonfocus

Telecamera 3D Photonfocus per applicazioni di triangolazione laser in ambienti scarsamente illuminati e su superfici riflettenti..
Software Design Assistant X

Ambiente di sviluppo IDE per sviluppo di applicazioni Machine Vision con diagrammi di flusso, senza bisogno di utilizzare codice di programmazione..
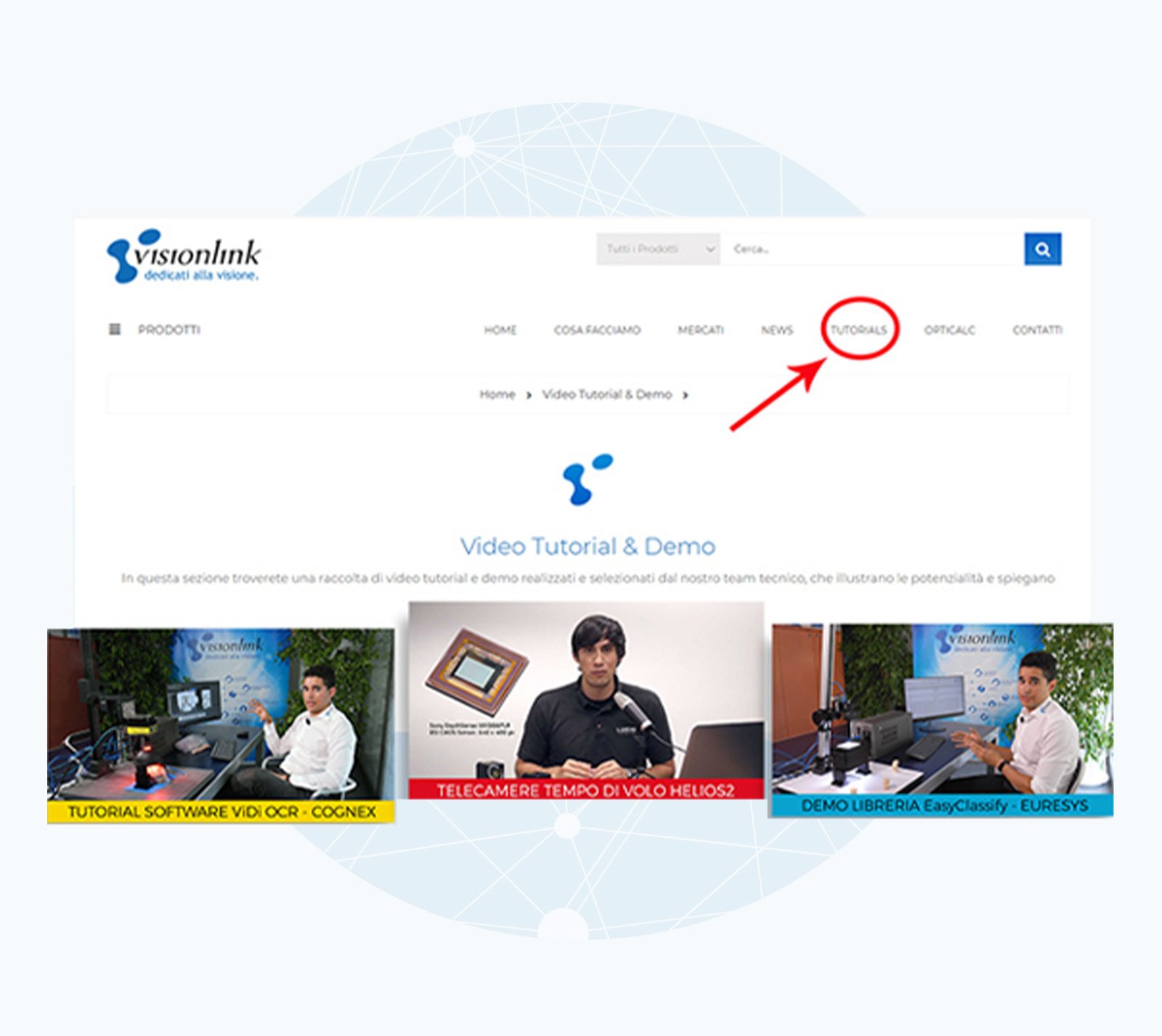
Tutorial & Demo
Registrati per accedere gratis ai video tutorial esclusivi realizzati e selezionati dai nostri tecnici. Buona visione!
ULTIME NEWS

16 Aprile 2024
Tecnologia di profilazione 3D per applicazioni machine vision
Che cos’è la profilazione 3D? La profilazione 3D è una delle principali tecnologie impiegate nella visione artificiale tridimensionale, insieme alla visione stereo, alla Time of Flight (ToF) e alla luce […]

9 Aprile 2024
Nuova distribuzione: illuminatori ProPhotonix
Seregno, Italia, 9 Aprile 2024 – Visionlink è lieta di annunciare la sua collaborazione con ProPhotonix come distributore ufficiale per l’Italia dei suoi innovativi sistemi di illuminazione per la visione artificiale. […]

26 Marzo 2024
La tecnologia 3D Time of Flight nei sistemi di visione artificiale
Che cos’è il tempo di volo (ToF)? Il tempo di volo (Time of Flight) è una tecnica di imaging che consente di ottenere immagini tridimensionali di oggetti senza la necessità […]
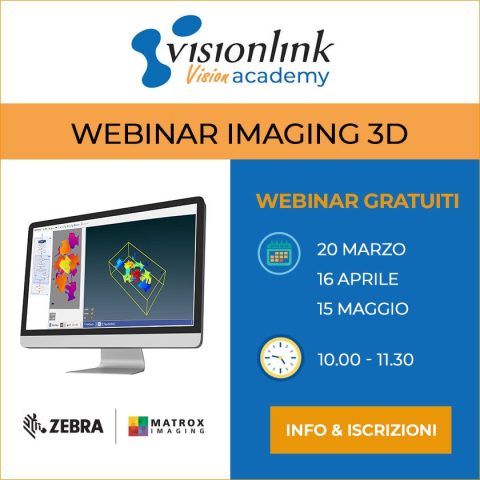
5 Marzo 2024
Nuovi webinar di imaging 3D con piattaforme Zebra Aurora
Siamo lieti di annunciare il lancio dei nostri nuovi webinar dedicati alle “Tecniche di acquisizione 3D attraverso le piattaforme Zebra Aurora“. Dopo il grande successo del training introduttivo sull’utilizzo dell’ambiente […]
MARCHI DISTRIBUITI

























